
希尔排序
希尔排序
一、概念及其介绍
希尔排序(Shell Sort)是插入排序的一种,它是针对直接插入排序算法的改进。
希尔排序又称缩小增量排序,因 DL.Shell 于 1959 年提出而得名。
它通过比较相距一定间隔的元素来进行,各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。
二、适用说明
希尔排序时间复杂度是 O(n^(1.3-2)),空间复杂度为常数阶 O(1)。希尔排序没有时间复杂度为 O(n(logn)) 的快速排序算法快 ,因此对中等大小规模表现良好,但对规模非常大的数据排序不是最优选择,总之比一般 O(n^2 ) 复杂度的算法快得多。
三、过程图示
希尔排序目的为了加快速度改进了插入排序,交换不相邻的元素对数组的局部进行排序,并最终用插入排序将局部有序的数组排序。
在此我们选择增量 gap=length/2,缩小增量以 gap = gap/2 的方式,用序列 {n/2,(n/2)/2…1} 来表示。
如图示例:
(1)初始增量第一趟 gap = length/2 = 4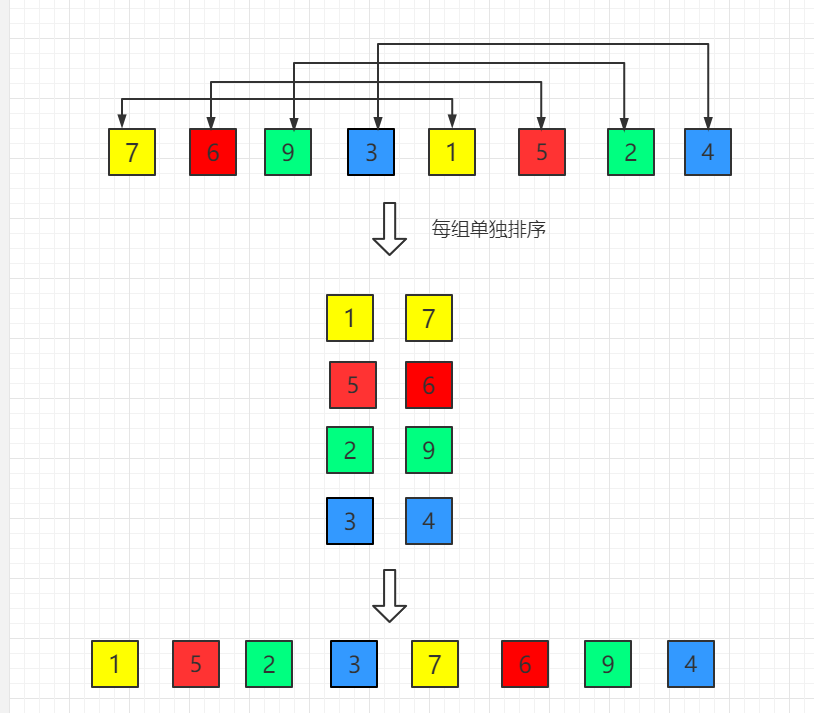
(2)第二趟,增量缩小为 2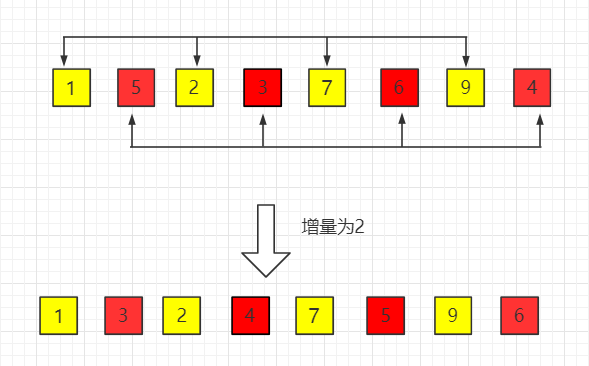
(3)第三趟,增量缩小为 1,得到最终排序结果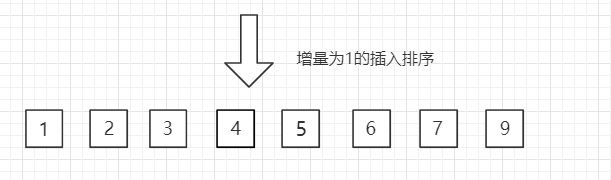
算法性能
时间复杂度
希尔排序的时间复杂度在不同情况下有所不同,但通常认为其平均时间复杂度为O(n^1.3)到O(nlog²n)之间。具体来说:
- 最坏情况:虽然希尔排序在某些情况下可能接近O(n²)的时间复杂度,但相较于传统的插入排序,其性能通常更优。
- 平均情况:希尔排序的平均时间复杂度通常在O(n^1.3)到O(nlog²n)之间,这使得它在处理中等规模数据时表现良好。
- 最好情况:在最佳情况下,希尔排序的时间复杂度可以达到较低的水平,但具体数值取决于实现方式和数据分布。
需要注意的是,希尔排序的时间复杂度受增量序列的选择影响较大。不同的增量序列可能导致不同的时间复杂度表现。
空间复杂度
希尔排序的空间复杂度为O(1),即它是一个原地排序算法。在排序过程中,希尔排序只需要常数级别的额外空间来存储临时变量,而不需要创建新的数组或数据结构来存储数据。这使得希尔排序在空间使用上非常高效。
稳定性
希尔排序是不稳定的排序算法。例如,考虑序列[3(a), 3(b), 1],假设初始 gap 为 2,那么第一次排序后可能得到[1, 3(b), 3(a)]。在这个过程中,相同元素 3 (a) 和 3 (b) 的相对顺序发生了改变,所以希尔排序不具有稳定性。在交换元素移动到较远位置时,可能会改变相同元素的相对顺序。
代码实现
1 | void shell_sort(vector<int>& v) { |

