
KMP算法详解
概述
对于字符串这一数据结构,寻找字符串中子串的位置是最重要的操作之一,查找子串位置的操作通常称为串的模式匹配。而KMP算法就是一种字符串模式匹配算法
朴素模式匹配
在介绍KMP算法之前,首先了解朴素模式匹配如何进行
思路解析
朴素的想法是用两个指针i,j分别指向主串和子串,如果两个指针指向的元素相同则指针后移,不相同则需要回退指针(主串指针回退到上次匹配首位的下一个位置,子串指针回退到开头位置),重复进行上述操作直到主串指针指向主串末尾
举个例子:主串S=“goodgoogle”,子串T=“google”
- 从主串S的第一位开始匹配,S和T的前三位都能匹配成功,第四位匹配失败,此时将主串的指针i退回到第二位,子串的指针j退回到起始位置(s[1])
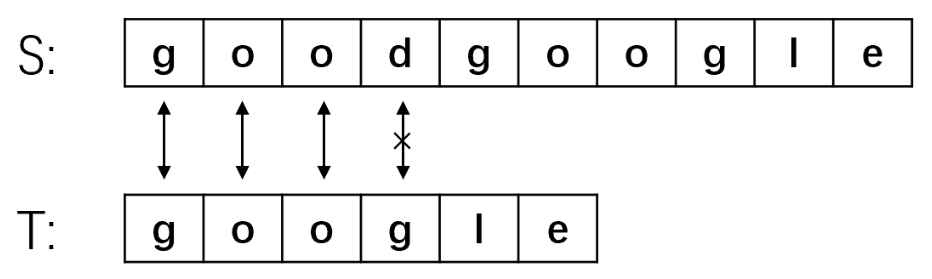
- 主串S从第二位开始于子串T匹配,第一步就匹配失败,将主串指针指向第三位S[2],子串指针指向开头,继续匹配
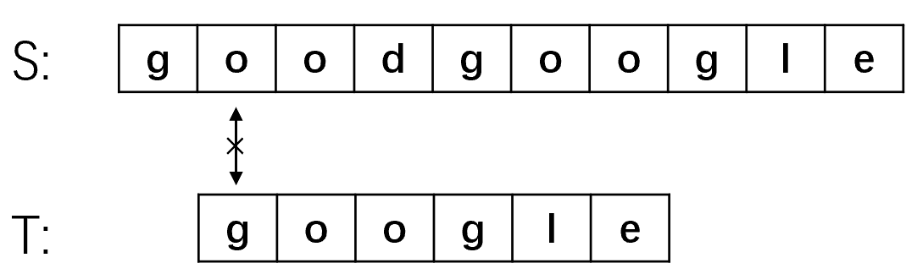
- 同步骤2,第一步就匹配失败,将主串指针移动到第四位S[3],子串指针指向开头,继续匹配

- 还是第一步就匹配失败,将主串指针移动到第五位S[4],子串指针指向开头,继续匹配
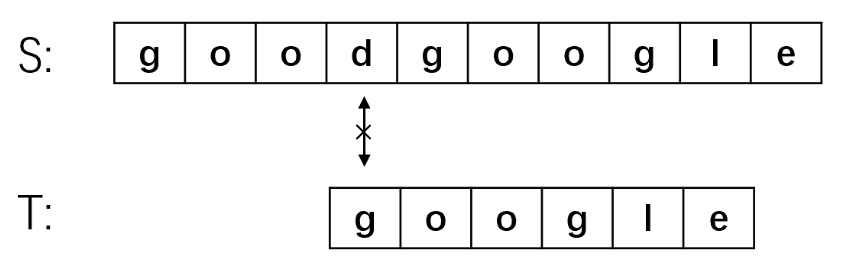
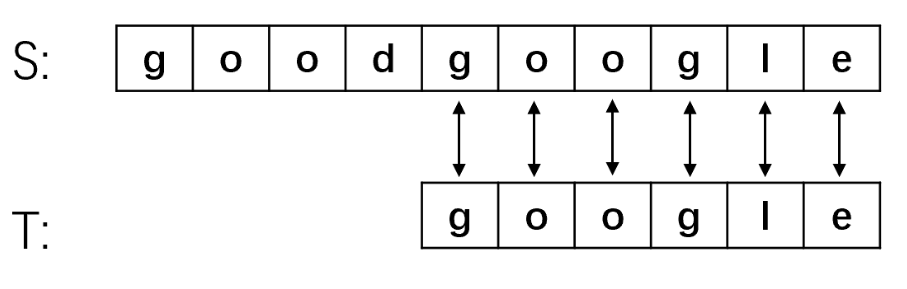
- 匹配成功!
代码实现
1 | // 朴素模式匹配算法函数 |
算法性能
既然是暴力做法,算法的开支相对较大。朴素模式匹配算法的时间复杂度为 O((n-m+1)*m),其中 n 是文本的长度,m 是模式的长度。在最坏的情况下(即每次匹配都失败),算法需要执行 n-m+1 次尝试,每次尝试都要比较 m 个字符
优化算法KMP
为了避免朴素算法的低效,几位计算机科学家前辈D.E.Knuth、J.H.MorTis和V.R.Pratt发表了一个模式匹配算法,可以一定程度上避免重复遍历的问题,该算法就是大名鼎鼎的KMP算法。
怎么优化?
KMP算法是朴素模式匹配的优化算法,既然这样就要知道优化在哪里。
之前的朴素算法过程如下:
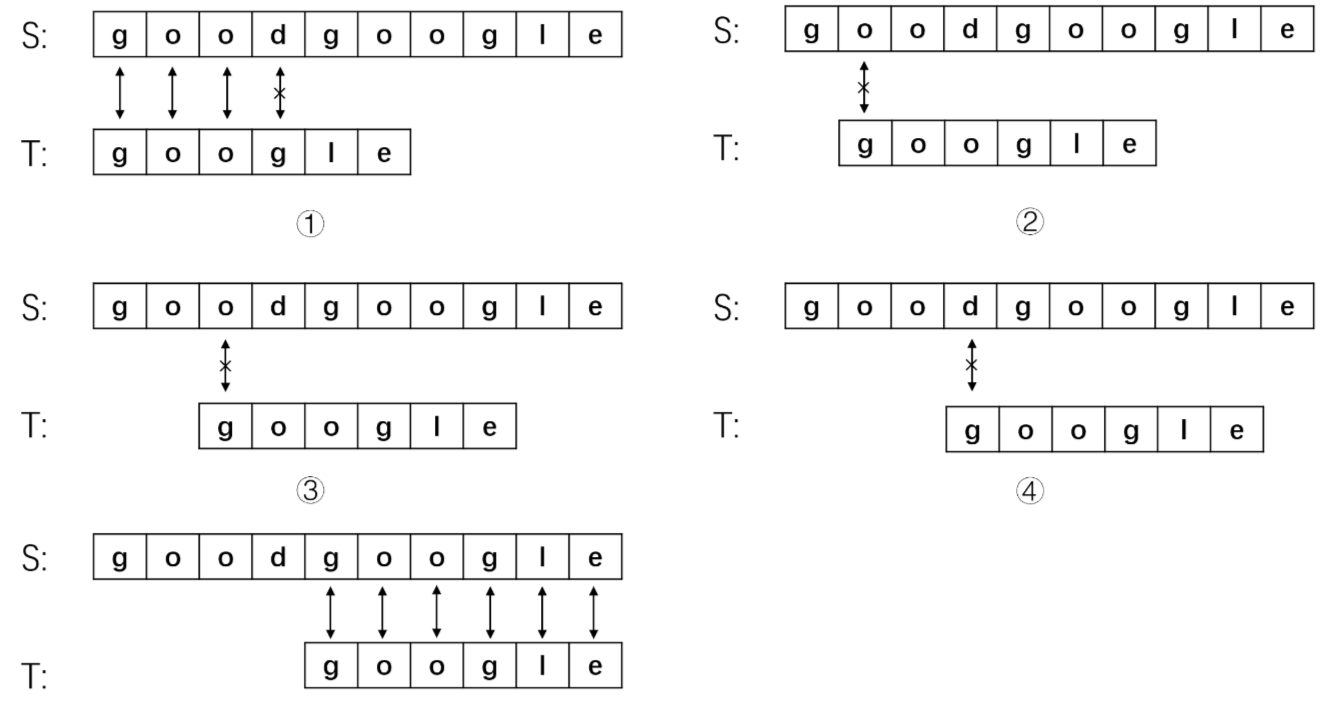
从上可知,在2、3、4步骤中,主串指针i指向的字符和子串的首字符都不匹配。也就是说这几步根本不需要执行,有没有一种办法可以让子串直接移到合适的地方呢?
再举一个例子:主串S=“abcababca”,子串T=“abcabx”。按照朴素算法如下:
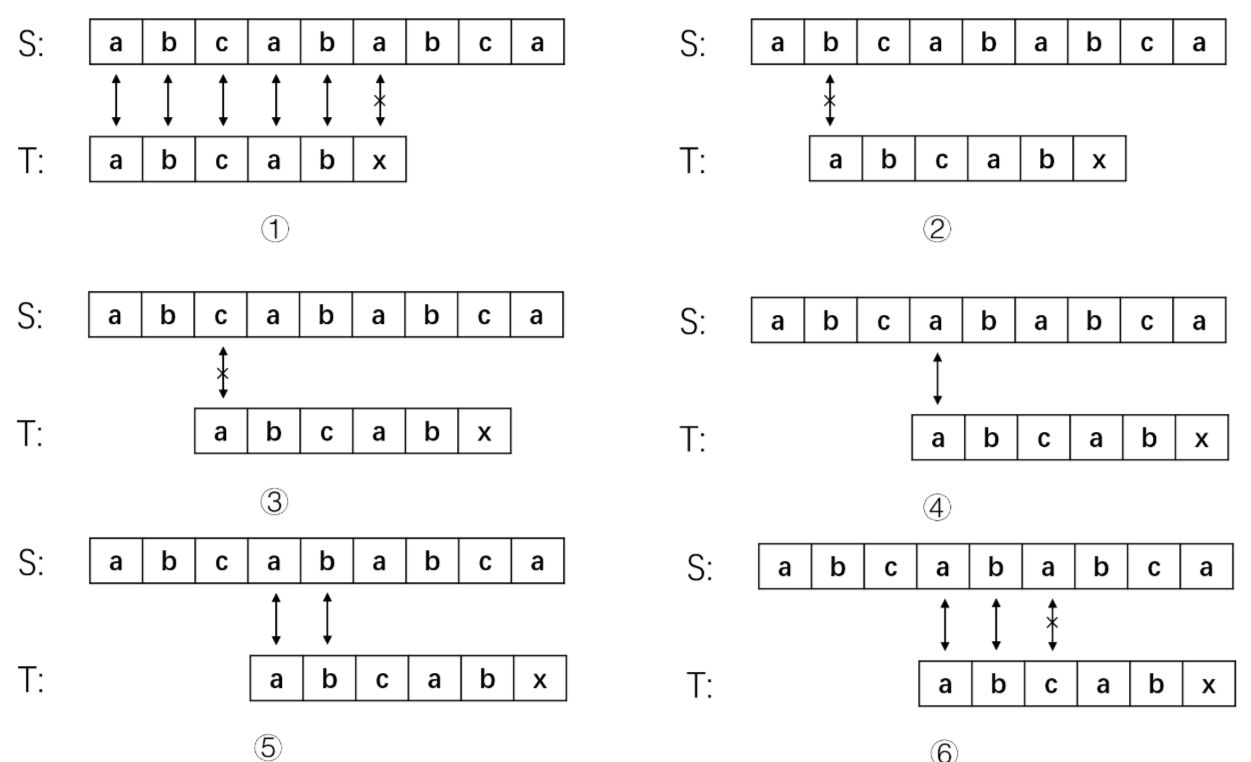
由之前一个例子的分析可知由于T串的首字母”a”与之后的字母”b”、”c”不等,故步骤2、3均是可以省略的。
又因为T的首位”a”与T第四位的”a”相等,第二位的”b”与第五位的”b”相等。而在步骤1中,第四位的”a”与第五位的”b”已经与主串s中的相应位置比较过了是相等的。因此可以断定, T的首字符“a”、第二位的字符“b”与S的第四位字符和第五位字符也不需要比较了,肯定也是相等的。所以步骤4、5这两个比较得出字符相等的步骤也可以省略
在这个例子中我们发现,在得知了子串中有相等的前后缀之后,匹配失败时子串指针不需要回退到开头处,而是回退到相等前缀的后一个位置
字符串的前缀就是不包含最后一个字符的所有子串,后缀就是不包含第一个字符的所有子串
算法原理
KMP引入一个额外的数组来记录如果匹配失败指针j该回溯到哪里,即next数组,记录的是字符串中的每个子串的最大相等前后缀的长度
举个例子:设字符串T=“abababab”,从下标0开始存储
- 当j=0,没有前缀和后缀可以比较,所以next[0]=0
- 当j=1,前缀“a”,后缀“b”,没有相等的前后缀,所以next[1]=0
- 当j=2,前缀“a”、“ab”,后缀“a”、“ba”,最长相等前后缀长度为1,所以next[2]=1
- 当j=3,前缀“a”、“ab”、“aba”,后缀“b”、“ab”、“bab”,最长相等前后缀长度为2,所以next[3]=2
- 以此类推:next[4]=3,next[5]=4,next[6]=5,next[7]=6
| next | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
设字符串S=“abababcabababab”
很明显:S[i] != T[j + 1]
i
a b a b a b c a b a b a b a b
a b a b a b a b
j
当i=6,j=6时发生了不匹配,根据next数组next[5],将j回溯到T[4]的位置。
i
a b a b a b c a b a b a b a b
a b a b a b a b
j
这样就可以不动指针i而只用回溯指针j
代码实现(都从0开始存储)
1 | int KMP(const string& s, const string& t) { |
算法性能
实战例题

相关链接:28. 找出字符串中第一个匹配项的下标 - 力扣(LeetCode)
1 | class Solution { |

